[ceph] ceph理解及总结
文章目录
ceph理解及总结
1.文档说明
本文档是对培训内容和ceph各种零散阅读的个人总结归纳。
精简了各知识点,以方便对ceph整体有个宏观认识,并可以根据知识点回忆起具体知识点内容。
2.参考文档
3.学习中产生的文档
4.ceph原理理解
4.1.ceph基本架构
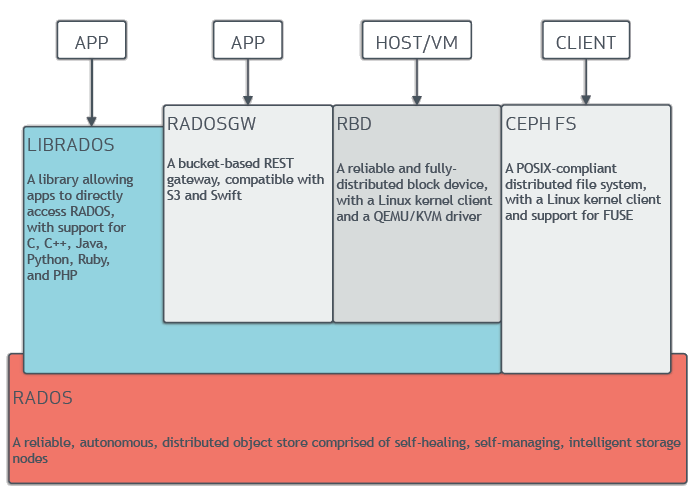
- 客户端:对象存储(rgw)、块存储(rbd)、文件系统(cephfs),通过直接调用librados库来访问存储
- rgw 接口与兼容s3和swift接口
- cephfs 支持用户级别和内核级别两种方式挂载
- librados 是Rados提供库,支持C,C++,java,Python,Ruby,PHP等访问
- rados 是可靠的、自组织的、可自动恢复、自我管理的分布式对象存储系统
4.2.ceph基本组成
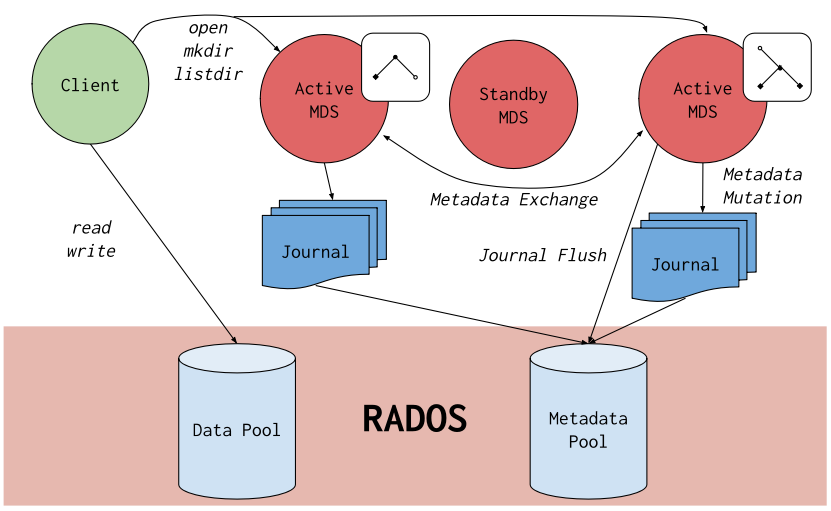
- mon(Monitor)
维护集群映射主副本,管理守护进程、客户机之间的身份验证和日志记录服务,mon集群保证了高可用。至少3个。
- mgr(Manager)
负责跟踪运行时指标和Ceph集群的当前状,包括存储利用率、当前性能指标和系统负载。还管理着的Ceph Dashboard和REST API。至少2个。
- osd(object Storage Device)
用于存储数据、处理数据复制、恢复、再平衡,并通过检查其他Ceph OSD daemon的心跳,为monitor和manager提供一些监控信息。通常至少需要3个ceph osd。
- mds(Ceph Metadata server)
CephFS服务依赖的元数据服务,管理文件元数据,支持用户基本命令(如ls、find等),以提高性能。
- pg(Placement Groups)
是一个逻辑的概念,一个PG 包含多个 OSD 。引入 PG 这一层其实是为了更好的分配数据和定位数据。
- pool
存储池,它是存储对象的逻辑分区,每个存储池都有很多归置组。
- object
Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据,对象包含唯一标识符,键值对的元数据,二进制数据。object的大小由RADOS限定(通常为2m或者4m)
- crush
是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的位置
- librados
Rados提供库,应用访问rados的入口
- rgw(Rados gateway)
- rbd(Rados Block Device)
- cephfs(Ceph File System)
4.3.ceph存储流程
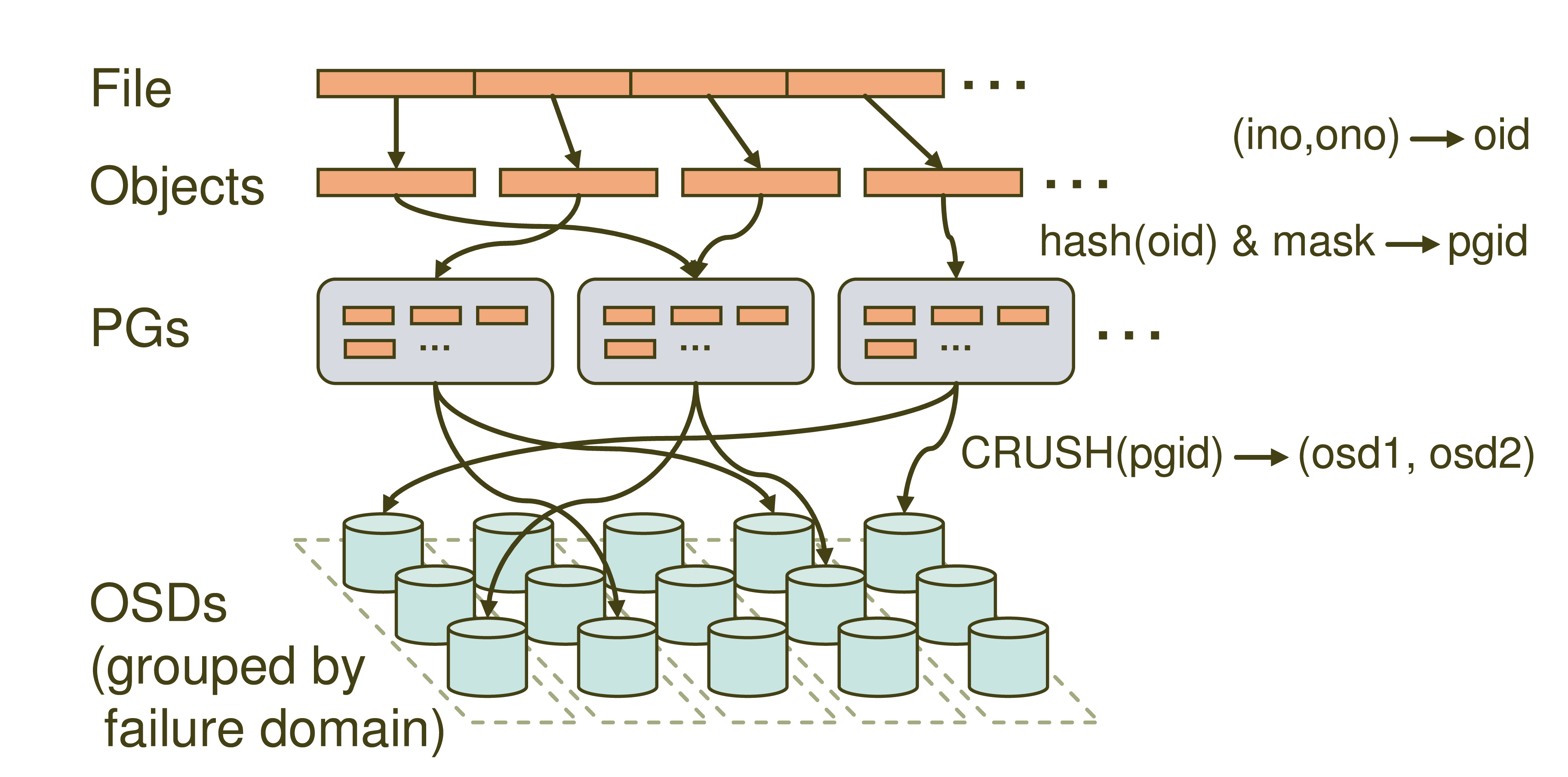
分为三个阶段
- File->Object
- 将file切分成多个object,每个object都有唯一的id即oid
- (ino(文件唯一id),ono(object序号))->oid
- 数据条带化
客户端将数据切割成多个条带单元,然后依次映射到对象集中
对象集中的对象容量应是条带单元的整数倍,且足够大
条带宽度应是对象尺寸的分片,条带数量确定条带要写入哪个对象集 条带化可以增加存储设备的吞吐量和性能 条带单元的尺寸是由客户端配置的,一般为64KB - Object->PG
- 根据oid计算一个hash值,并根据目标池id以及pgnum计算获得目标PGID
- PG->OSD
- 根据PGID以及crush rule,计算目标osd位置
|
|
4.4.ceph的特点
-
高可扩展性和高可用性
- 消除集中网关
Ceph 消除了集中网关,允许客户端直接和 Ceph OSD 守护进程通讯
为消除中心节点, Ceph 使用了 CRUSH 算法 mon持有集群运行图的主副本,和OSD守护程序共同维护集群运行图- 高可用监视器
ceph支持mon集群
客户端和守护进程通过Ceph配置文件来发现监视器,监视器成员使用监视器映射(monmap)发现彼此
monmap强一致性要求,使用Paxos算法来使集群监视器对集群映射达成共识- 高可用性用户认证
Ceph 用 cephx 认证系统来认证用户和守护进程
Cephx 用共享密钥来认证,即客户端和监视器集群各自都有客户端密钥的副本 每个监视器都能认证用户、发布会话密钥,所以使用 cephx 时不会有单点故障或瓶颈 -
智能程序支撑超大规模
- Ceph 客户端、监视器和 OSD 守护进程可以相互直接交互
- Ceph 允许客户端直接和 OSD 节点联系,这在消除单故障点的同时,提升了性能和系统总容量
- OSD彼此做心跳检测并报告MON,MON也定ping OSD,这种机制意味着监视器还是轻量级进程
- OSD 每天比较对象元数据发现osd缺陷或文件系统错误,OSD每周按位比较对象中的数据做深度清洗
- 客户端把对象写入目标归置组的主OSD ,然后这个主 OSD 再用它的 CRUSH 图副本找出用于放对象副本的第二、第三个 OSD,全部副本存储成功后反馈客户端
- Ceph 存储集群应该保存两份以上的对象副本(如 size = 3 且 min size = 2 )
- 新增一OSD守护进程时,集群运行图就要用新增的 OSD 更新,PG会进行重均衡
4.5.集群运行图
- Montior Map
包含集群的 fsid 、位置、名字、地址和端口,也包括当前版本、创建时间、最近修改时间。要查看监视器图,用 ceph mon dump 命令。
- OSD Map
包含集群 fsid 、创建时间、最近修改时间、存储池列表、副本数量、归置组数量、 OSD 列表及其状态(如 up 、 in )。要查看OSD运行图,用 ceph osd dump 命令。
- PG Map
包含归置组版本、其时间戳、最新的 OSD 运行图版本、占满率、以及各归置组详情,像归置组 ID 、 up set 、 acting set 、 PG 状态(如 active+clean ),和各存储池的数据使用情况统计。
- CRUSH Map
包含存储设备列表、故障域树状结构(如设备、主机、机架、行、房间、等等)、和存储数据时如何利用此树状结构的规则。要查看 CRUSH 规则,执行 ceph osd getcrushmap -o {filename} 命令;然后用 crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename} 反编译;然后就可以用 cat 或编辑器查看了。
- MDS Map
包含当前 MDS 图的版本、创建时间、最近修改时间,还包含了存储元数据的存储池、元数据服务器列表、还有哪些元数据服务器是 up 且 in 的。要查看 MDS 图,执行 ceph mds dump 。
5.本地ceph环境安装成果
5.1.基本配置
| 操作系统 | 内核版本 | 主机名 | 网段IP | 磁盘 | 服务 |
|---|---|---|---|---|---|
| centos 7.9 | 3.10.0 | node1 | 10.0.8.116 | 系统盘: sda;osd盘: sdb | mon1,osd0,rgw1,mds1,mgr1,dashboard,smb-server |
| centos 7.9 | 3.10.0 | node2 | 10.0.8.159 | 系统盘: sda;osd盘: sdb | mon2,osd1,rgw2 |
| centos 7.9 | 3.10.0 | node3 | 10.0.8.122 | 系统盘: sda;osd盘: sdb | mon3,osd2,rgw3,fs-client,block-client |
| windows10 | - | - | 10.0.6.229 | - | smb-client(fs-client) |
5.2.ceph集群状态
|
|
5.3.cephfs和smb
|
|
5.4.rgw
|
|
5.5.rdb
|
|
5.6.dashboard
文章作者 ZhangKQ
上次更新 2022-02-10