Ceph之成长之路
一、ceph基础概念了解
1.Ceph是什么?
Ceph是一个统一的分布式存储系统(Distributed File System,DFS),设计初衷是提供较好的性能、可靠性和可扩展性。
2.Ceph有哪些特点?
-
高性能
- a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
- b. 考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
- c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
-
高可用性
- a. 副本数可以灵活控制。
- b. 支持故障域分隔,数据强一致性。
- c. 多种故障场景自动进行修复自愈。
- d. 没有单点故障,自动管理。
-
高可扩展性
- a. 去中心化。
- b. 扩展灵活。
- c. 随着节点增加而线性增长。
-
特性丰富
- a. 支持三种存储接口:块存储、文件存储、对象存储。
- b. 支持自定义接口,支持多种语言驱动。
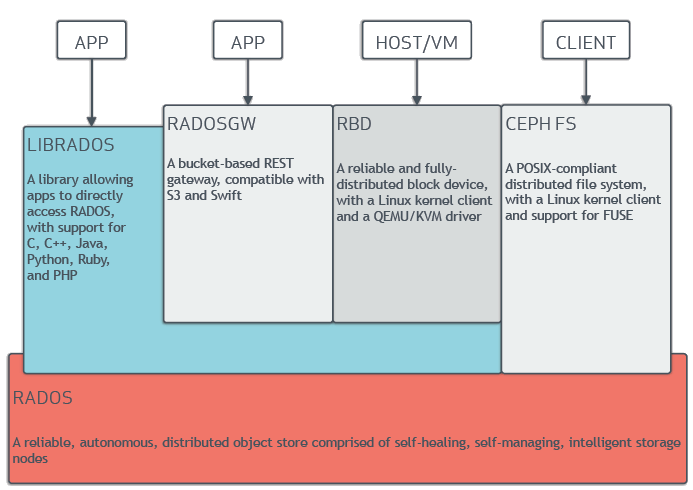
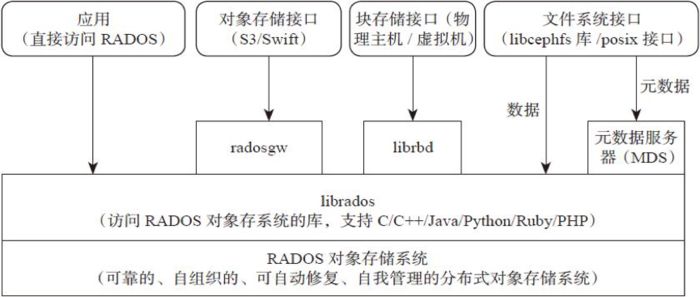
3.Ceph的架构
支持三种接口:
- Object:有原生的API,而且也兼容Swift和S3的API。
- Block:支持精简配置、快照、克隆。
- File:Posix接口,支持快照。





4.基本概念有哪些?
-
Monitor [ˈmɒnɪtə(r)]
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,管理和客户机的身份验证,维护集群映射的主副本。
-
OSD
OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。
-
MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务,管理文件元数据。
-
Object
Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据。
-
Mgr
Ceph Manager守护进程(ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载
-
RAID
磁盘冗余阵列
-
POOL
存储池,它是存储对象的逻辑分区,每个存储池都有很多归置组
-
PG
PG全称Placement Grouops,是一个逻辑的概念,一个间接层,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
-
RADOS
RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,一种稳定、可扩展、高性能、高度自治的对象(Object)存储系统,用户实现数据分配、Failover等集群操作。
-
Librados
Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
-
CRUSH
CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
-
RBD
RBD全称RADOS block device,是Ceph对外提供的块设备服务。
-
RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
-
CephFS
CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
5.三类存储类型
- 块存储:通过Raid与LVM等手段对数据提供了保护,读写高速,成本高,主机之间无法共享数据
- 文件存储:造价低,文件共享,读写速率低,传输速率慢
- 对象存储:读写高速,文件共享
二、ceph体系结构了解
1 cepth存储集群
Ceph 存储集群包含两种类型的守护进程:
Ceph 监视器:维护着集群运行图的主副本。一个监视器集群确保了当某个监视器失效时的高可用性。存储集群客户端向 Ceph 监视器索取集群运行图的最新副本。
Ceph OSD 守护进程:守护进程检查自身状态、以及其它 OSD 的状态,并报告给监视器们
1.1 数据的存储
1.2 伸缩性和高可用性
-
伸缩性
去中心化,消除了集中网关,允许客户端直接和 Ceph OSD 守护进程通讯。
CRUSH 用智能数据复制确保弹性,更能适应超大规模存储
-
高可用
OSD自动在其他节点创建对象副本,保证数据安全和高可用
监视器也实现了集群化,保证高可用
为消除中心节点, Ceph 使用了 CRUSH 算法
-
CRUSH 简介
Ceph 客户端和 OSD 守护进程都用 CRUSH 算法来计算对象的位置信息,不依赖于一个中心化的查询表。
-
集群运行图
Ceph 依赖于 Ceph 客户端和 OSD ,因为它们知道集群的拓扑,这个拓扑由 5 张图共同描述,统称为“集群运行图”
五张图:Montior Map,OSD Map,PG Map,CRUSH Map,MDS Map
Ceph 监视器维护着一份集群运行图的主拷贝,包括集群成员、状态、变更、以及 Ceph 存储集群的整体健康状况。
-
高可用监视器
Ceph 客户端读或写数据前必须先连接到某个 Ceph 监视器、获得最新的集群运行图副本
Ceph 总是使用大多数监视器和Paxos 算法就集群的当前状态达成一致
-
高可用性认证
Ceph用cephx认证系统来认证用户和守护进程。
cephx 协议不解决传输加密(如 SSL/TLS )、或者存储加密问题。
Cephx 用共享密钥来认证,即客户端和监视器集群各自都有客户端密钥的副本。
-
智能程序支撑超大规模
1.OSD 直接服务于客户端
消除单故障点的同时,提升了性能和系统总容量
2.OSD 成员和状态
Ceph 监视器能周期性地 ping OSD 守护进程
OSD 进程去确认邻居 OSD 是否 down 了,并更新集群运行图、报告给监视器
3.数据清洗
Ceph OSD 能比较对象元数据与存储在其他 OSD 上的副本元数据,以捕捉 OSD 缺陷或文件系统错误(每天)
OSD 也能做深度清洗(每周),即按位比较对象中的数据,以找出轻度清洗时未发现的硬盘坏扇区
4.复制
主 OSD 用它的 CRUSH 图副本找出所有副本 OSD进行数据复制
1.3 动态集群管理
1.4 纠删编码
纠删码存储池把各对象存储为 K+M 个数据块,其中有 K 个数据块和 M 个编码块
比如一纠删码存储池创建时分配了五个 OSD ( K+M = 5 )并容忍其中两个丢失( M = 2 )
1.5 缓存分级
缓存分层包含由相对高速、昂贵的存储设备(如固态硬盘)创建的存储池,并配置为 缓存层
后端存储池,可以用纠删码编码的或者相对低速、便宜的设备,作为经济存储层
Ceph 对象管理器会决定往哪里放置对象,分层代理决定何时把缓存层的对象刷回后端存储层
缓存层和后端存储层对 Ceph 客户端来说是完全透明的

1.6 扩展ceph
通过创建 ‘Ceph Classes’ 共享对象类来扩展 Ceph 功能
Ceph 会动态地载入位于osd class dir目录下的 .so类文件(即默认的 $libdir/rados-classes)
1.7 小结
Ceph 存储集群是动态的——像个生物体。尽管很多存储设备不能完全利用一台普通服务器上的 CPU 和 RAM 资源,但是 Ceph 能。从心跳到互联、到重均衡、再到错误恢复, Ceph 都把客户端(和中央网关,但在 Ceph 架构中不存在)解放了,用 OSD 的计算资源完成此工作。
2 ceph 协议
Ceph 客户端用原生协议和存储集群交互, Ceph 把此功能封装进了 librados 库

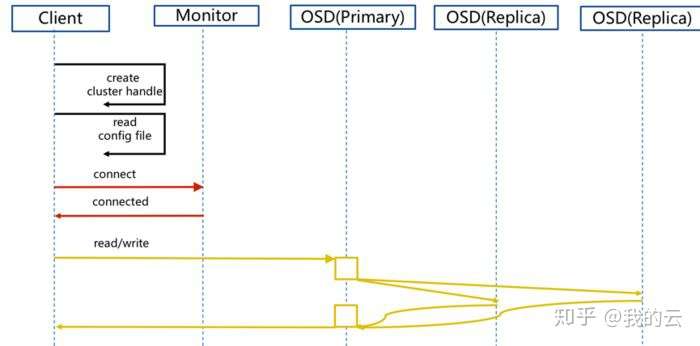
Ceph 客户端把数据等分为条带单元并映射到对象后,用 CRUSH 算法把对象映射到归置组、归置组映射到 OSD ,然后才能以文件形式存储到硬盘上
2.1 原生协议和librados
现代程序都需要可异步通讯的简单对象存储接口。 Ceph 存储集群提供了一个有异步通讯能力的简单对象存储接口,此接口提供了直接、并行访问集群对象的功能。
2.2 对象监视/通知
客户端可以注册对某个对象的持续兴趣,并使到主 OSD 的会话保持打开。客户端可以发送一通知消息和载荷给所有监视者、并可收集监视者的回馈通知。这个功能使得客户端可把任意对象用作同步/通讯通道。

2.3 数据条带化
条带化: 把连续的信息分片存储于多个设备,以增加吞吐量和性能
Ceph 的条带化提供了像 RAID 0 一样的吞吐量、像 N 路 RAID 镜像一样的可靠性、和更快的恢复
Ceph把写入分布到多个对象(它们映射到了不同归置组和 OSD ),这样可减少每设备寻道次数、联合多个驱动器的吞吐量,以达到更高的写(或读)速度
把集群投入生产环境前要先测试条带化配置的性能,因为把数据条带化到对象中之后这些参数就不可更改了。
3.ceph 客户端
Ceph 客户端包括数种服务接口,有:
- 块设备: Ceph块设备(RBD)服务提供了大小可调、精炼、支持快照和克隆的块设备。为提供高性能, Ceph 把块设备条带化到整个集群。 Ceph 同时支持内核对象( KO ) 和 QEMU 管理程序直接使用
librbd ——避免了内核对象在虚拟系统上的开销。
- 对象存储: Ceph 对象存储(RGW )服务提供了
RESTful 风格_的 API ,它与 Amazon S3 和 OpenStack Swift 兼容。
- 文件系统: Ceph 文件系统(CephFS)服务提供了兼容 POSIX 的文件系统,可以直接 mount 或挂载为用户空间文件系统( FUSE )。

3.1 ceph对象存储
Ceph 对象存储守护进程,radosgw ,是一个 FastCGI 服务,它提供了 RESTful 风格_ HTTP API 用于存储对象和元数据
它位于 Ceph 存储集群之上,有自己的数据格式,并维护着自己的用户数据库、认证、和访问控制
RADOS 网关使用统一的命名空间,兼容 Swift和S3 的API
3.2 ceph 块存储
Ceph 块设备把一个设备映像条带化到集群内的多个对象,其中各对象映射到一个归置组并分布出去,这些归置组会分散到整个集群的 ceph-osd 守护进程上。
3.3 ceph 文件系统

MDS 的作用是把所有文件系统元数据(目录、文件所有者、访问模式等等)永久存储在相当可靠的元数据服务器中内存中。
MDS存在的原因是,简单的文件系统操作像(ls,cd)这些操作会不必要的扰动OSD。所以把元数据从数据里分出来意味着 Ceph 文件系统能提供高性能服务,又能减轻存储集群负载。
MDS待命( standby )和活跃( active ) MDS 可组合
三、ceph集群运维
1.集群健康状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
[root@node1 ~]# ceph -s
cluster:
id: 35051854-874a-4919-b8a1-fb60c737034d //集群id
health: HEALTH_OK //集群状态
services:
mon: 3 daemons, quorum node1,node2,node3 (age 5d) //mon数量及成员
mgr: node1(active, since 5d) //mgr 成员及运行时
mds: cephfs:1 {0=node1=up:active} //mds 文件系统,数量及成员,状态
osd: 3 osds: 3 up (since 5d), 3 in (since 9d) //osd数量及状态,运行时
rgw: 3 daemons active (node1, node2, node3) //rgw数量,成员及状态
task status:
data:
pools: 10 pools, 480 pgs //存储池数量及pg数量
objects: 364 objects, 321 MiB //对象数量及占用容量
usage: 3.7 GiB used, 26 GiB / 30 GiB avail //实际使用的原始存储量 , (表示群集的整体存储容量的可用量(较小的数量))/ (复制,克隆或快照之前存储的数据的大小)
pgs: 480 active+clean //pg数量及状态
|
1
2
|
集群日志,该日志记录有关整个系统的高级事件, 存储在磁盘(/var/log/ceph/ceph.log默认情况下)
ceph log last [n]查看集群日志中的最新行
|
2.集群使用情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
[root@node1 ~]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 30 GiB 26 GiB 679 MiB 3.7 GiB 12.21
TOTAL 30 GiB 26 GiB 679 MiB 3.7 GiB 12.21
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.rgw.root 1 32 1.2 KiB 4 512 KiB 0 12 GiB
default.rgw.control 2 32 0 B 8 0 B 0 12 GiB
default.rgw.meta 3 32 2.0 KiB 9 1.0 MiB 0 12 GiB
default.rgw.log 4 32 0 B 207 0 B 0 12 GiB
cephfs_data 5 64 26 B 1 128 KiB 0 12 GiB
cephfs_metadata 6 64 34 KiB 23 1.1 MiB 0 12 GiB
default.rgw.buckets.index 7 32 0 B 2 0 B 0 12 GiB
default.rgw.buckets.data 8 32 307 MiB 85 614 MiB 2.36 12 GiB
default.rgw.buckets.non-ec 9 32 0 B 0 0 B 0 12 GiB
rbd 10 128 10 MiB 25 34 MiB 0.13 8.3 GiB
输出的RAW STORAGE部分提供了群集管理的存储量的概述。
**类别:**OSD设备的类别(或群集的总数)
**大小:**集群管理的存储容量。
**可用:**自由空间的集群中使用的量。
**已用:**用户数据消耗的原始存储量。
未使用的原始资源**:**用户数据,内部开销或保留的容量消耗的原始存储量。
**已用%RAW:**已用原始存储空间的百分比。将此数字与和结合使用,以确保未达到群集的容量。有关更多详细信息,请参见存储容量。fullratio``nearfullratio
输出的POOLS部分提供了池的列表以及每个池的名义用法。本节的输出不反映副本,克隆或快照。例如,如果您存储的对象具有1MB的数据,则名义使用量将为1MB,但实际使用量可能为2MB或更多,具体取决于副本,克隆和快照的数量。
**NAME:**池的名称。
**ID:**池ID。
USED:存储在千字节,除非有数字数据附加的名义量中号为兆字节或ģ千兆字节。
%USED:每个池使用的名义存储百分比。
**MAX AVAIL:**可以写入此池的名义数据量的估计值。
**对象:**每个池中存储的对象的名义数量。
|
四、ceph 原理理解
1 集群运行图
1.1 mon map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
通过 ceph mon dump <epoch> 查看monmap 信息
[root@node1 ~]# ceph mon dump
epoch 2 //dump map的版本号,cluster map的epoch是一个单调递增序列。epoch越大,则cluster map版本越新。monitor手中必定有epoch最大、版本最新的cluster map。当任意两方在通信时发现彼此epoch值不同时,将默认先将cluster map同步至高版本一方的状态,再进行后续操作
fsid 35051854-874a-4919-b8a1-fb60c737034d //fsid 是集群的惟一标识,它是 Ceph 作为文件系统时的文件系统标识符
last_changed 2021-12-10 18:54:26.361872
created 2021-12-10 16:55:05.306706
min_mon_release 14 (nautilus)
0: [v2:10.0.8.116:3300/0,v1:10.0.8.116:6789/0] mon.node1
1: [v2:10.0.8.159:3300/0,v1:10.0.8.159:6789/0] mon.node2
2: [v2:10.0.8.122:3300/0,v1:10.0.8.122:6789/0] mon.node3
dumped monmap epoch 2
[root@node1 ~]# ceph mon stat
e2: 3 mons at {node1=[v2:10.0.8.116:3300/0,v1:10.0.8.116:6789/0],node2=[v2:10.0.8.159:3300/0,v1:10.0.8.159:6789/0],node3=[v2:10.0.8.122:3300/0,v1:10.0.8.122:6789/0]}, election epoch 76, leader 0 node1, quorum 0,1,2 node1,node2,node3
|
1.2 mds map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
通过 ceph fs dump 查看mdsmap 信息
[root@node1 ~]# ceph fs dump
e4
enable_multiple, ever_enabled_multiple: 0,0
compat: compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
legacy client fscid: 1
Filesystem 'cephfs' (1)
fs_name cephfs
epoch 4
flags 12
created 2021-12-13 11:12:05.092833
modified 2021-12-13 11:12:06.215835
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
min_compat_client -1 (unspecified)
last_failure 0
last_failure_osd_epoch 0
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=4296}
failed
damaged
stopped
data_pools [5]
metadata_pool 6
inline_data disabled
balancer
standby_count_wanted 0
[mds.node1{0:4296} state up:active seq 58174 addr [v2:10.0.8.116:6808/1903314498,v1:10.0.8.116:6809/1903314498]]
dumped fsmap epoch 4
[root@node1 ~]# ceph mds stat
cephfs:1 {0=node1=up:active}
|
1.3 mgr dump
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
通过 ceph mgr dump <epoch> 查看mgrmap信息
[root@node1 ~]#ceph mgr dump
{
"epoch": 22,
"active_gid": 14103,
"active_name": "ceph4",
"active_addr": "10.1.1.24:6804/7416",
"available": true,
"standbys": [],
"modules": [
"balancer",
"dashboard",
"restful",
"status"
],
"available_modules": [
"balancer",
"dashboard",
"influx",
"localpool",
"prometheus",
"restful",
"selftest",
"status",
"zabbix"
],
"services": {
"dashboard": "http://node1:8443/"
},
"always_on_modules": {
"nautilus": [
"balancer",
"crash",
"devicehealth",
"orchestrator_cli",
"progress",
"rbd_support",
"status",
"volumes"
]
}
}
|
1.4 osd map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
通过 ceph osd dump 查看osdmap信息
OSD状态的描述分为两个维度:up或者down(表明OSD是否正常工作),in或者out(表明OSD是否承载(在)至少一个pg)
[root@node1 ~]# ceph osd dump
epoch 73
fsid 35051854-874a-4919-b8a1-fb60c737034d
created 2021-12-10 16:55:23.081379
modified 2021-12-14 16:02:55.158962
flags sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit
crush_version 7
full_ratio 0.95
backfillfull_ratio 0.9
nearfull_ratio 0.85
require_min_compat_client jewel
min_compat_client jewel
require_osd_release nautilus
pool 1 '.rgw.root' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode warn last_change 16 flags hashpspool stripe_width 0 application rgw
pool 5 'cephfs_data' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode warn last_change 30 flags hashpspool stripe_width 0 application cephfs
pool 6 'cephfs_metadata' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode warn last_change 30 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfs
max_osd 3
osd.0 up in weight 1 up_from 59 up_thru 67 down_at 57 last_clean_interval [50,56) [v2:10.0.8.116:6800/26852,v1:10.0.8.116:6801/26852] [v2:10.0.8.116:6802/26852,v1:10.0.8.116:6803/26852] exists,up 338dc846-e848-4067-9dd1-66213cbc0ba7
osd.1 up in weight 1 up_from 63 up_thru 67 down_at 61 last_clean_interval [52,60) [v2:10.0.8.159:6800/11651,v1:10.0.8.159:6801/11651] [v2:10.0.8.159:6802/11651,v1:10.0.8.159:6803/11651] exists,up 7061bbca-c1d6-44c2-ae3b-b5fdcd6c2e87
osd.2 up in weight 1 up_from 65 up_thru 67 down_at 63 last_clean_interval [55,62) [v2:10.0.8.122:6800/11521,v1:10.0.8.122:6801/11521] [v2:10.0.8.122:6802/11521,v1:10.0.8.122:6803/11521] exists,up 282588a4-b13f-41bc-9dfb-65eb2a25d4ed
[root@node1 ~]# ceph osd stat
3 osds: 3 up (since 5d), 3 in (since 9d); epoch: e73
[root@node1 ~]# ceph osd tree //osd节点分布情况以及当前状态, 包含权重的crush树
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.02939 root default
-3 0.00980 host node1
0 hdd 0.00980 osd.0 up 1.00000 1.00000
-5 0.00980 host node2
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.00980 host node3
2 hdd 0.00980 osd.2 up 1.00000 1.00000
|
1.5 pg map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
通过 ceph pg map {pg-num} 查看pgmap信息
[root@node1 ~]# ceph pg dump
version 249561
stamp 2021-12-20 11:26:13.055013
last_osdmap_epoch 0
last_pg_scan 0
PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP SNAPTRIMQ_LEN
10.7f 0 0 0 0 0 0 0 0 7 7 active+clean 2021-12-20 10:38:54.937740 73'7 73:42 [2,1,0] 2 [2,1,0] 2 73'7 2021-12-20 10:38:54.937691 00 2021-12-14 16:00:17.388784 0
10.7e 0 0 0 0 0 0 0 0 9 9 active+clean 2021-12-19 08:10:36.418629
10 25 0 0 0 0 15106084 0 0 1062 1062
9 0 0 0 0 0 0 0 0 42 42
8 85 0 0 0 0 321700730 0 0 173 173
7 2 0 0 0 0 0 0 0 105 105
6 23 0 0 0 0 34698 35 1 111 111
5 1 0 0 0 0 26 0 0 6 6
1 4 0 0 0 0 1245 0 0 5 5
2 8 0 0 0 0 0 0 0 580 580
3 9 0 0 0 0 1729 357 2 29 29
4 207 0 0 0 0 0 0 0 98063 98063
sum 364 0 0 0 0 336844512 392 3 100176 100176
OSD_STAT USED AVAIL USED_RAW TOTAL HB_PEERS PG_SUM PRIMARY_PG_SUM
2 239 MiB 8.8 GiB 1.2 GiB 10 GiB [0,1] 359 165
1 216 MiB 8.8 GiB 1.2 GiB 10 GiB [0,2] 367 165
0 224 MiB 8.8 GiB 1.2 GiB 10 GiB [1,2] 362 150
sum 679 MiB 26 GiB 3.7 GiB 30 GiB
* NOTE: Omap statistics are gathered during deep scrub and may be inaccurate soon afterwards depending on utilisation. See http://docs.ceph.com/docs/master/dev/placement-group/#omap-statistics for further details.
dumped all
结果将告诉您放置组的总数(x),处于特定状态(例如active+cleany)的放置组数和已存储的数据量(z)
除了放置组状态之外,Ceph还将回显已使用的存储容量(aa),剩余存储容量(bb)和该放置组的总存储容量。这些数字在某些情况下可
[root@node1 ~]# ceph pg stat
480 pgs: 480 active+clean; 321 MiB data, 679 MiB used, 26 GiB / 30 GiB avail
|
1.6 crush map
1
2
3
4
5
6
|
#Ceph将输出(-o)已编译的CRUSH映射到您指定的文件名
ceph osd getcrushmap -o compiled_crushmap.txt
#反编译CRUSH映射
crushtool -d compiled_crushmap.txt -o decompiled_crushmap.txt
#读取CRUSH映射
cat decompiled_crushmap.txt
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host node1 { //每个类型的桶只包含低一级类型的桶、以及其内条目的权重之和
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.010
alg straw2 //桶类型:Uniform(用完全相同的权重汇聚设备),List(把它们的内容汇聚为链表),Tree(它用一种二进制搜索树),Straw( list 和 tree 桶用分而治之策略,给特定条目一定优先级), Straw2(Straw改进型, 方便数据移动)
hash 0 # rjenkins1 //各个桶都用了一种哈希算法,当前 Ceph 仅支持 rjenkins1 ,输入 0 表示哈希算法设置为 rjenkins1
item osd.0 weight 0.010 //权重和设备容量不同,我们建议用 1.00 作为 1TB 存储设备的相对权重,这样 0.5 的权重大概代表 500GB 、 3.00 大概代表 3TB 。较高级桶的权重是所有枝叶桶的权重之和。
}
host node2 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.010
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.010
}
host node3 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.010
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.010
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item node1 weight 0.010
item node2 weight 0.010
item node3 weight 0.010
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
|
-
crush map 解读
CRUSH MAP 中包含以下几个部分:
- Tunables: 可调整的参数列表
- Devices: 存储设备列表,列举了集群中所有的OSD
- Types: 类型定义,一般0为OSD,其它正整数代表host、chassis、rack等, type 12 enclosure表示盘框,是我们产品自定义的一种类型
- 有效的CRUSHtype, 包括根目录(root),地区(region), 分区(zone), 数据中心(datacenter),房间(room),行(row),窗格(pod),数据单元(pdu),机架(rack),机箱(chassis)和主机(host), osd (or device)
- Buckets: 容器列表,指明了每个bucket下直接包含的children项及其权重值(非OSD的items统称为bucket),bucket 是层次结构中内部节点(主机,机架,行等)的CRUSH术语
- Rules: 规则列表,每个规则定义了一种选取OSD的方式, 规则定义有关数据如何在层次结构中的各个设备之间分配的策略
-
crush rule 解读
crush rule,用以确定一个存储池里数据的归置,规则定义了归置和复制策略、或分布策略,用它可以规定 CRUSH 如何放置对象副本。
你可能创建很多存储池,且每个存储池都有它自己的 CRUSH 规则集和规则。新创建存储池的默认规则集是 0
1
2
3
4
5
6
7
8
9
10
|
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
|
CRUSH rule定义了一种选择策略,Ceph中每个逻辑池(Pool)都必须对应一条合法的rule才能正常工作。解读如下:
- rule replicated_rule 是定义的规则名称
- id 0 是rule规则的id
- type replicated rule的类型,replicated代表适用于副本池,erasure代表适用于EC池
- min_size 1 max_size 10 rule适用的池size大小;本例表示1副本到10副本的池均可采用此条
- rule step take default 直接选中一项item,一般用于指定选择算法的起点;本例中名为default的root类型bucket即为起点
1
2
3
4
5
6
7
8
9
10
|
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item node1 weight 0.010
item node2 weight 0.010
item node3 weight 0.010
}
|
- step chooseleaf firstn 0 type host 选择策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
step chooseleaf firstn 0 type host 可以分解为 step <1> <2> <3> type <4>
<1>: choose/chooseleaf
choose表示选择结果类型为故障域(由<4>指定)
chooseleaf表示在确定故障域后,还必须选出该域下面的OSD节点(即leaf)
<2>: firstn/indep
firstn: 适用于副本池,选择结果中rep(replica,指一份副本或者EC中的一个分块,下同)位
置无明显意义
indep: 适用于EC池,选择结果中rep位置不可随意变动
实现上二者都是深度优先,并无显著区别
<3>: num_reps
这个整数值指定需要选择的rep数目,可以是正值负值或0。
正整数值即代表要选择的副本数,非常直观
0表示的是与实际逻辑池的size相等;也就是说,如果2副本池用了这个rule,0就代表了2;如
果3副本池用了此rule,0就相当于3
负整数值代表与实际逻辑池size的差值;如果3副本池使用此rule将该值设为了-1,那边该策
略只会选择出2个reps
<4>: failure domain
指定故障域类型;CRUSH确保同一故障域最多只会被选中一次。
选择的具体算法在这里暂不说明
|
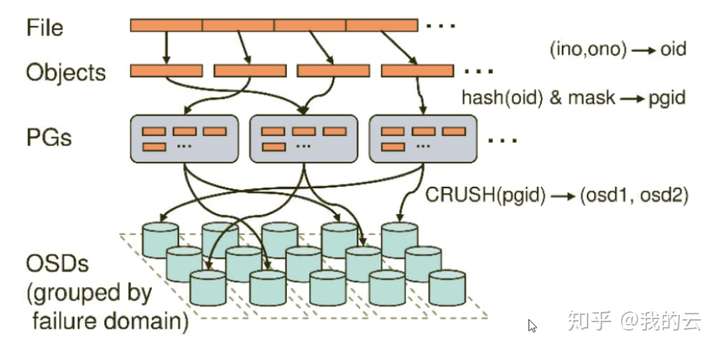
2 pg 理解
2.1 pg概念
Ceph 对集群中所有存储资源进行池化管理。存储池(Pool) 实际上是逻辑概念,表示一组约束条件。
Ceph将任意类型的前端数据都抽象为对象,每个对象采用一定的策略可以生成全局唯一的对象标识(即
ObjectID, OID),基于此全局唯一的OID可以形成一个扁平的寻址空间,从而提升索引效率。但是从pool
到对象之间,粒度太大,ceph需要一个容器,因此引入了PG作为中间结构
- 客户端根据各自的规则负责生成oid
- 根据oid计算一个hash值,并根据目标池id以及pgnum计算获得目标PGID
- 根据PGID以及crush rule,计算目标osd
- 整个计算流程都是在客户端完成的
1
2
3
4
5
6
|
locator = object_name = filename + objectid
obj_hash = hash(locator)
pgid = obj_hash & num_pg
OSDs_for_pg = crush(pgid) # returns a list of OSDs
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]
|
2.2 PG num 计算
2.2.1 说明
PG num 是使用者在创建pool时需要指定的参数,num不是独立的,而是需要结合pool所使用的osd数
量及数据量来考虑,过多的num意味着会耗费更多的系统资源在管理pg上,同时osd损坏后需要迁移和
恢复更多的pg,意味着风险的增加,过少的num可能会降低恢复的效率,同时单个pg管理的对象也增
多,同样意味着风险的增加。另外,社区认为pg num应当设置为2的幂,这在上面计算object target时
会增加效率,同时在扩展pool的pg num时会很有用。
2.2.2 total pg num 计算公式
1
|
( Target PGs per OSD ) x ( OSD # ) x ( %Data ) / ( Size )
|
- 当前设计的目标target pg per osd 为64个
- 若计算结果小于osd / size, 应当置为osd / size
- 最终结果应当是2的幂
- 若是多个pool复用了同一组osd,应当根据各自所占比例x %Data
- 若最近的2的幂比原始值低25%以上,选择更高一层的2的幂
- 若最终结果反推回的pgs per osd 低于30,选择更高一层的2的幂,直到满足条件
2.2.3 相关设置
1
2
3
4
5
6
7
|
mon_pg_warn_min_per_osd = 30 #每个osd的pg最低数量,低于此值会报警
mon_max_pg_per_osd = 800 #每个osd的pg最大数量
mon_pg_warn_max_per_osd = 800 #每个osd的pg最大数量,高于此值会报警
mon_max_pool_pg_num = 65536 #每个存储池的最大pg数量
mon_warn_on_pool_pg_num_not_power_of_two = true #警告存储池的pg数量不是2的幂
mon_target_pg_per_osd = 100 #autoscaler自动调整的默认比例(pg和osd的)
osd_pool_default_pg_autoscale_mode = warn #pg自动扩容, 值可选on、off、warn
|
2.2.4 autoscale
N版本之前,pgnum只支持扩展,不支持缩减,现在两者都支持,而且支持自动扩缩容
1
2
|
ceph osd pool set <pool-name> pg_autoscale_mode <mode> 指定pool设置
ceph config set global osd_pool_default_pg_autoscale_mode <mode> 全局设置
|
mode 可选on、off、warn
2.3 PG术语、概念与状态迁移
pg概念
ceph创建存储池需要pg数和pgp数的两个参数。
PG (Placement Group),pg是一个虚拟的概念,用于存放object
PGP(Placement Group for Placement purpose),相当于是pg存放的一种osd排列组合
pg和pgp的影响
- PG是指定存储池存储对象的归属组有多少个,PGP是存储池PG的OSD分布组合个数
- PG的增加会引起PG内的数据进行迁移,迁移到不同的OSD上新生成的PG中
- PGP的增加会引起部分PG的分布变化,但是不会引起PG内对象的变动。
pg均衡
OSD之间的均匀分配都需要更多的放置组,但应将其数量减少到最少,以节省CPU和内存
数据持久性:
- 更多的OSD意味着恢复速度更快,而导致级联组永久丢失的级联故障的风险更低
- 如果该群集增长到200个OSD,恢复将比有40个OSD时花费更长的时间,这意味着应该增加放置组的数量
3.BlueStore
OSD 管理存储对象数据方式有:
- BlueStore(Luminous 12.2.z后):构建在裸磁盘设备之上,并且对诸如SSD等新的存储设备做了很多优化工作
- Filestore(Luminous 12.2.z之前):依赖于标准文件系统(通常是 XFS)和键/值数据库(传统的 LevelDB,现在是 RocksDB),存在许多性能缺陷
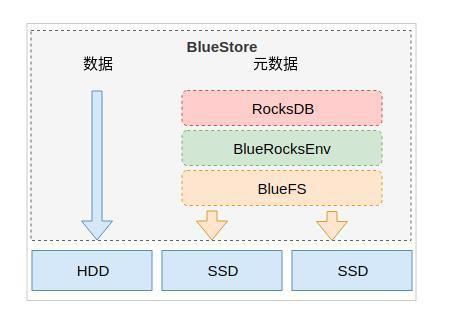
BlueStore 主要功能包括
- 直接管理存储设备,提高了性能和降低了复杂性
- 使用 RocksDB 进行元数据管理
- 完整的数据校验和元数据校验,读取必须校验
- 数据在写入磁盘之前可以选择压缩
- 多设备元数据分层,日志和原数据可以写入高速设备,以提高性能
- 高效的写时复制,这为常规快照和纠删码池带来了高效的 IO



